Rangkuman Model Linier
Pada artikel ini akan membahas beberapa Metode Linear diantaranya :

Meskipun tampaknya menjadi metrik yang sangat baik untuk evaluasi
tetapi mungkin tidak diinginkan untuk setiap kasus penggunaan.
Katakanlah, kami berusaha mendeteksi apakah seseorang menderita kanker
atau tidak. Katakanlah, kami mencoba untuk mengklasifikasikan 1.000
orang dengan kanker atau tidak dan kami dapat memperoleh akurasi 95%.
Meskipun ini mungkin terlihat seperti model yang sangat bagus tetapi
ini adalah tangkapannya. Jika sebagian besar sampel negatif (tidak ada
kanker) dan model memperkirakannya negatif, akurasinya akan tinggi
bahkan jika beberapa sampel positif diprediksi negatif. Ini tidak
diinginkan karena kami tidak ingin memberi tahu orang yang menderita
kanker bahwa ia tidak menderita kanker tetapi kami dapat meminta orang
yang tidak menderita kanker untuk menjalani beberapa tes, jika
diperlukan. Jadi, kami ingin memilih model yang mencoba untuk tidak
memprediksi kasus positif sebagai negatif, yaitu, memiliki daya ingat
yang lebih tinggi.
 Ruang ROC didefinisikan oleh FPR dan TPR masing-masing sebagai
sumbu x dan y, yang menggambarkan trade-off relatif antara true
positive (benefit) dan false positive (costs). Kurva ROC dibuat
dengan memplot true positive rate (TPR) terhadap false positive
rate (FPR) di berbagai pengaturan ambang batas. AUC adalah area
di bawah Kurva ROC. Skor AUC yang lebih tinggi menandakan model
yang lebih baik.
Ruang ROC didefinisikan oleh FPR dan TPR masing-masing sebagai
sumbu x dan y, yang menggambarkan trade-off relatif antara true
positive (benefit) dan false positive (costs). Kurva ROC dibuat
dengan memplot true positive rate (TPR) terhadap false positive
rate (FPR) di berbagai pengaturan ambang batas. AUC adalah area
di bawah Kurva ROC. Skor AUC yang lebih tinggi menandakan model
yang lebih baik.
Jika Anda ingin melihat pendekatan yang berfungsi untuk masalah klasifikasi biner, lihat ini.
- Curve Fitting dan Eroor Function
- Binary Classification
Curve Fitting dan Error Function

menghasilkan fungsi linear g(x); seperti Gambar 5.2 (garis berwarna
hijau). Akan tetapi, fungsi approksimasi ini tidak 100% tepat sesuai
dengan fungsi aslinya (ini perlu ditekankan)1 . Jarak antara titik biru
terhadap garis hijau disebut error.


Salah satu cara menghitung error fungsi g(x) adalah menggunakan squared error function dengan bentuk konseptual pada
persamaan 5.1. Estimasi terhadap persamaan tersebut disajikan dalam
bentuk diskrit pada persamaan 5.2. (xi,yi) adalah pasangan training
data (input - desired output). Nilai squared error dapat menjadi tolak
ukur untuk membandingkan kinerja suatu learning machine (model). Secara
umum, bila nilainya tinggi, maka kinerja dianggap relatif buruk;
sebaliknya bila rendah, kinerja dianggap relatif baik. Hal ini sesuai
dengan konsep intelligent agent [5].
1 Kamu patut curiga apabila model pembelajaran mesinmu memberikan performa 100%

Secara konseptual, bentuk fungsi regresi dilambangkan sebagai persamaan 5.3 [9].

Persamaan 5.3 dibaca sebagai “expectation of y, with the distribution of q”. Secara statistik, regresi dapat disebut sebagai ekspektasi untuk y berdasarkan/ dengan input x. Perlu diperhatikan kembali, regresi adalah pendekatan sehingga belum tentu 100% benar (hal ini juga berlaku pada model machine learning pada umumnya). Kami telah memberikan contoh fungsi linear sederhana, yaitu g(x) = xw + b. Pada kenyataannya, permasalahan kita lebih dari persoalan skalar. Untuk x (input) yang merupakan vektor, biasanya kita mengestimasi dengan lebih banyak variable, seperti pada persamaan 5.4. Persamaan tersebut dapat ditulis kembali dalam bentuk aljabar linear sebagai persamaan 5.5.

Bentuk persamaan 5.4 dan 5.5 relatif interpretable karena setiap fitur pada input (xi) berkorespondensi hanya dengan satu parameter bobot wi. Artinya, kita bisa menginterpretasikan seberapa besar/kecil pengaruh suatu fitur xi terhadap keputusan (output) berdasarkan nilai wi. Hal ini berbeda dengan algoritma non-linear (misal artificial neural network, bab 11) dimana satu fitur pada input bisa berkorespondensi dengan banyak parameter bobot. Perlu kamu ingat, model yang dihasilkan oleh fungsi linear lebih mudah dimengerti dibanding fungsi non-linear. Semakin, suatu model pembelajaran mesin, berbentuk non-linear, maka ia semakin susah dipahami.
Ingat kembali bab 1, learning machine yang direpresentasikan dengan fungsi g bisa diatur kinerjanya dengan parameter training w. Squared error untuk learning machine dengan parameter training w diberikan oleh persamaan 5.2. (xi,yi) adalah pasangan input-desired output. Selain untuk menghitung squared error pada training data, persamaan 5.2 juga dapat digunakan untuk menghitungsquared error pada testing data. Tujuan dari regresi/machine learning secara umum adalah untuk meminimalkan nilailoss atau error baik pada training maupun unseen instances. Secara umum, kita lebih ingin meminimalkan loss, dimana error dapat menjadi proxy untuk loss. Selain error function, ada banyak fungsi lainnya seperti Hinge, Log Loss, Cross-entropy loss, Ranking loss [1].
1 Kamu patut curiga apabila model pembelajaran mesinmu memberikan performa 100%

Secara konseptual, bentuk fungsi regresi dilambangkan sebagai persamaan 5.3 [9].
Persamaan 5.3 dibaca sebagai “expectation of y, with the distribution of q”. Secara statistik, regresi dapat disebut sebagai ekspektasi untuk y berdasarkan/ dengan input x. Perlu diperhatikan kembali, regresi adalah pendekatan sehingga belum tentu 100% benar (hal ini juga berlaku pada model machine learning pada umumnya). Kami telah memberikan contoh fungsi linear sederhana, yaitu g(x) = xw + b. Pada kenyataannya, permasalahan kita lebih dari persoalan skalar. Untuk x (input) yang merupakan vektor, biasanya kita mengestimasi dengan lebih banyak variable, seperti pada persamaan 5.4. Persamaan tersebut dapat ditulis kembali dalam bentuk aljabar linear sebagai persamaan 5.5.

Bentuk persamaan 5.4 dan 5.5 relatif interpretable karena setiap fitur pada input (xi) berkorespondensi hanya dengan satu parameter bobot wi. Artinya, kita bisa menginterpretasikan seberapa besar/kecil pengaruh suatu fitur xi terhadap keputusan (output) berdasarkan nilai wi. Hal ini berbeda dengan algoritma non-linear (misal artificial neural network, bab 11) dimana satu fitur pada input bisa berkorespondensi dengan banyak parameter bobot. Perlu kamu ingat, model yang dihasilkan oleh fungsi linear lebih mudah dimengerti dibanding fungsi non-linear. Semakin, suatu model pembelajaran mesin, berbentuk non-linear, maka ia semakin susah dipahami.
Ingat kembali bab 1, learning machine yang direpresentasikan dengan fungsi g bisa diatur kinerjanya dengan parameter training w. Squared error untuk learning machine dengan parameter training w diberikan oleh persamaan 5.2. (xi,yi) adalah pasangan input-desired output. Selain untuk menghitung squared error pada training data, persamaan 5.2 juga dapat digunakan untuk menghitungsquared error pada testing data. Tujuan dari regresi/machine learning secara umum adalah untuk meminimalkan nilailoss atau error baik pada training maupun unseen instances. Secara umum, kita lebih ingin meminimalkan loss, dimana error dapat menjadi proxy untuk loss. Selain error function, ada banyak fungsi lainnya seperti Hinge, Log Loss, Cross-entropy loss, Ranking loss [1].
Binary Classification
- Menguji apakah seseorang memiliki penyakit tertentu atau tidak
- Mengklasifikasikan email sebagai spam atau bukan spam
- Deteksi penipuan kartu kredit, dll.
- Diberikan seperangkat pengamatan
- Sebuah model perlu dilatih berdasarkan pengamatan tersebut
- Posting yang mana model harus dapat mengklasifikasikan pengamatan baru ke dalam salah satu kategori.
Beberapa metode yang paling umum digunakan untuk klasifikasi biner
adalah :
- k-Nearest Neighbour
- Naive Bayes
- Logistic Regression
- Decision Trees
- Random Forests
- SVMs
- Neural Networks
Evalution
Metrik evaluasi yang paling sederhana dan paling umum untuk masalah
klasifikasi biner adalah akurasi.
Akurasi = (# Prediksi Benar) / (# Pengamatan)
Katakanlah bahwa pengamatan memiliki sampel positif (P) dan negatif
(N). Model ini memberikan dua jenis prediksi: prediksi positif (P
') dan prediksi negatif (N'). Berdasarkan prediksi, kita dapat
membuat matriks kebingungan :
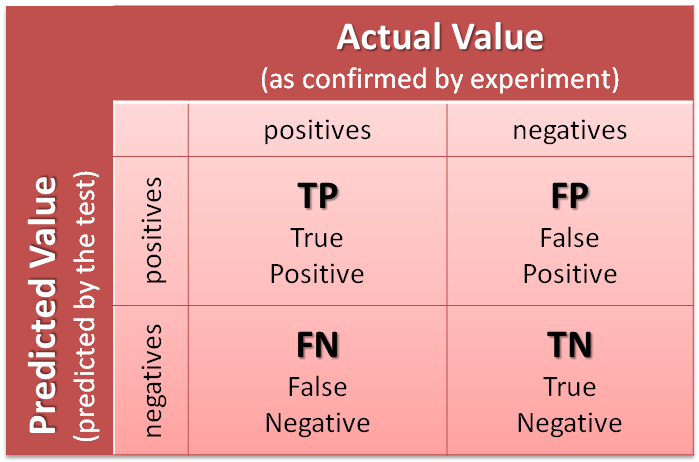
Confusion Matrix (Source:MathWorks)
- True Positive (TP) : Positive and Predicted Positive
- True Negative (TN) : Negative and Predicted Negative
- False Positive (FP) : Negative and Predicted Positive
- False Negative (FN) : Positive and Predicted Negative
- P + N = # Observations
- TP + TN = True (Correct) Predictions
- FP + FN = False (Incorrect) Predictions
- TP + FN = P
- TN + FP = N
- TP + FP = P’
- TN + FN = N’
Oleh karena itu, Akurasi (ACC) = (TP + TN) / (P + N)
Kita dapat memperoleh 8 metrik yang lebih berguna berdasarkan
TP, FP, TN, FN. Ini adalah :
- Recall/Sensitivity/Hit Rate/True Positive Rate (TPR) = TP/P
- Miss Rate/False Negative Rate (FNR) = FN/P
- Specificity (SPC)/True Negative Rate (TNR) = TN/N
- Fall-out/False Positive Rate (FPR) = FP/N
- Precision/Positive predictive value (PPV) = TP/P’
- False Discovery Rate (FDR) = FP/P’
- Negative predictive value (NPV) = TN/N’
- False Omission Rate (FOR) = FN/N’
Derivasi Lebih Lanjut :
- Positive Likelihood ratio (LR+) = TPR/FPR
- Negative Likelihood ratio (LR-) = FNR/TNR
ROC Curve (Source:Wikipedia)
Jika Anda ingin melihat pendekatan yang berfungsi untuk masalah klasifikasi biner, lihat ini.
0 Response to "Rangkuman Model Linier"
Posting Komentar